

比特币Rollup Citrea在测试网上部署了基于BitVM的桥接器“Clementine”。
Anthropic,一家由前OpenAI研究人员创立的领先人工智能研究公司,昨天宣布推出了Claude 3.5 Sonnet,这是Claude AI家族中最新、最先进的模型。这次重大升级紧随OpenAI的GPT-4o发布之后,GPT-4o是一种本地多模态大型语言模型(LLM),最近在LMSys chatbot arena中夺得了榜首。
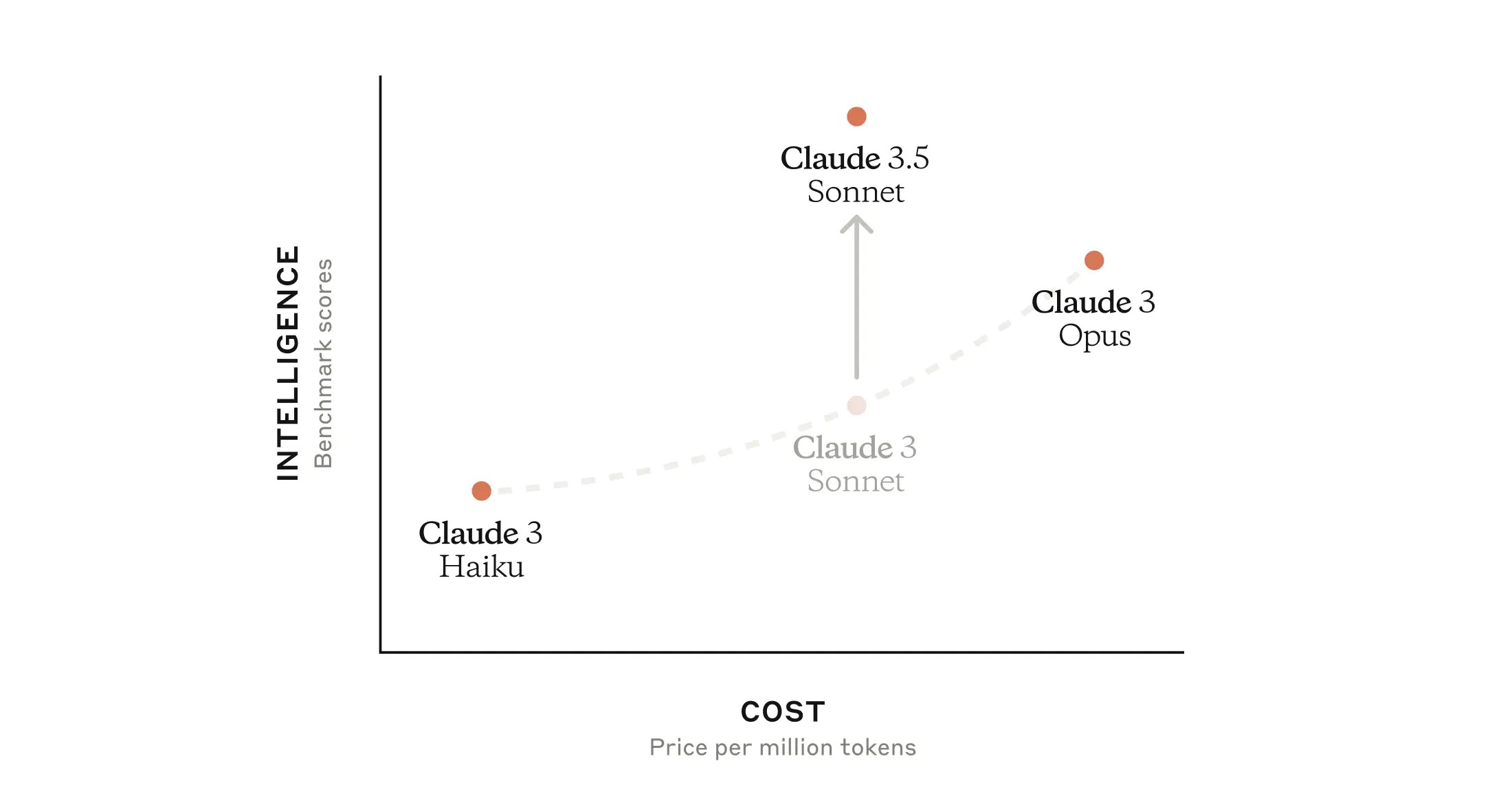
Claude 3.5 Sonnet定位为中端模型,介于Haiku(专为高效任务设计的小型模型)和Opus(Anthropic付费版本的高端模型,价格为每月20美元)之间。目前,Haiku和Opus仅提供3.0版本,使Sonnet 3.5成为它们在能力、知识和效率方面最佳的模型。
Anthropic声称,他们的新模型在几乎所有合成基准测试中击败了GPT-4o,特别是在使用多次提示技术时——即提供多个示例。
这些合成基准测试衡量模型在不同领域的性能。通过设定一定数量的条件和测试,可以获得定量值来衡量定性变量。换句话说,这些基准测试不是说哪个模型在任务上看起来更好或更好,而是说一个模型在可衡量的方式上有多好。
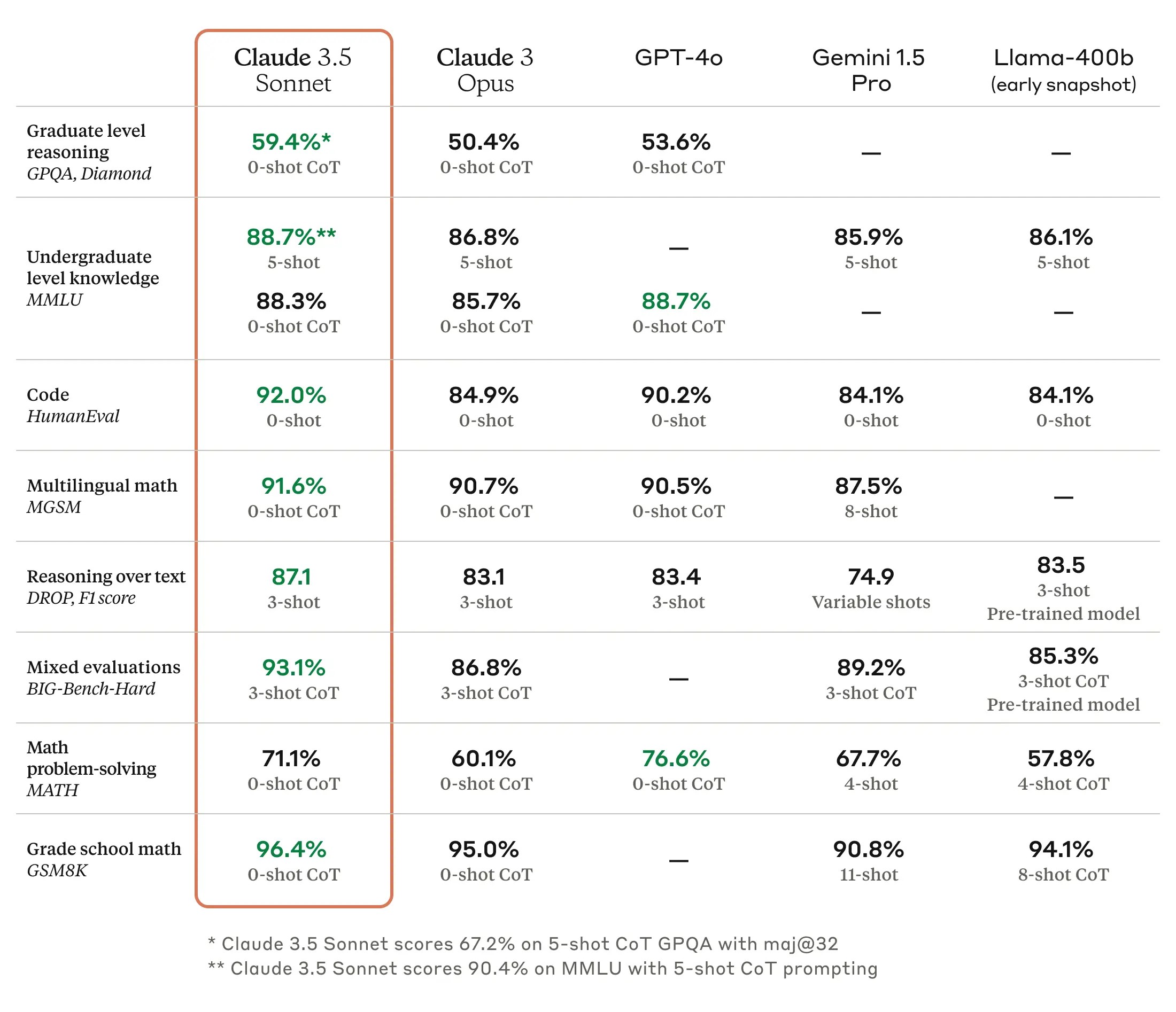
在性能方面,Anthropic表示,Claude 3.5 Sonnet的运行速度是前一顶级模型Claude 3 Opus的两倍,提供更多的性能,而成本仅为前者的五分之一。这使其成为处理复杂任务的理想选择,例如上下文敏感的客户支持和需要与模型进行大量互动的专业任务。
其创作者表示,与前身相比,它在理解微妙之处、幽默和复杂指令方面也有显著改进。
Claude 3.5 Sonnet还提供先进的视觉处理和理解能力。Anthropic表示,它特别擅长解释图表、图形,并从不完美的图像中转录文本。现在,该公司的顶级模型可以理解视觉提示的上下文,而不仅仅是描述事物。这使其直接与ChatGPT和Reka在多模态能力方面竞争。
例如,我们向Claude提供了一张地图,并询问在该位置可以做些什么。它发现地图是芝加哥的,并给出了一些建议,比如使用公共交通而不是出租车,或者参观Wicker Park、Lincoln Park和Hyde Park。

该模型还具有先进的编码能力。根据Anthropic的说法,它可以独立编写、编辑和执行具有复杂推理和故障排除能力的代码,前提是提供相关工具。这个功能使其能够优化开发人员的工作流程并加速编码任务。
Claude 3.5 Sonnet引入的一个新功能是“Artifacts”。这使用户可以实时查看、编辑和构建Claude生成的内容。它将AI创建的输出直接集成到项目和工作流程中,特别适用于与代码交互,并为Claude提供了比ChatGPT或Reka等传统聊天机器人更精致的用户界面。
Anthropic预计将在今年晚些时候发布Claude 3.5的Haiku和Opus版本。如果Sonnet能挑战GPT-4o,Opus有可能成为未来GPT迭代(如假设的GPT-5)的坚实竞争对手。
总的来说,这两个模型都展示了令人印象深刻的能力,但在各种任务中它们相互对抗时表现如何呢?让我们探讨它们在编码、创意写作和专业任务中的表现。
Claude 3.5 Sonnet目前在处理大量用户流量和长时间交互方面存在一些限制。Claude的免费版本为用户提供了更受限的体验,与付费版本相比,令牌上下文更小,可用提示更少。特别是如果用户分析长文档或处理代码时,这一点尤为明显。
ChatGPT的免费版本为用户提供了更丰富的令牌和提示分配,允许进行更长、更复杂的交互,而无需付费升级。OpenAI也提供“Plus”订阅,但在达到限制之前需要更长的时间才会被要求升级。
获胜者:ChatGPT赢得了这一轮。其免费版本提供了更大的容量和可访问性,使其对于不愿意或无法支付高级AI服务的用户更加友好。Claude的方法似乎旨在鼓励用户升级到付费层,这可能对一些用户构成障碍。
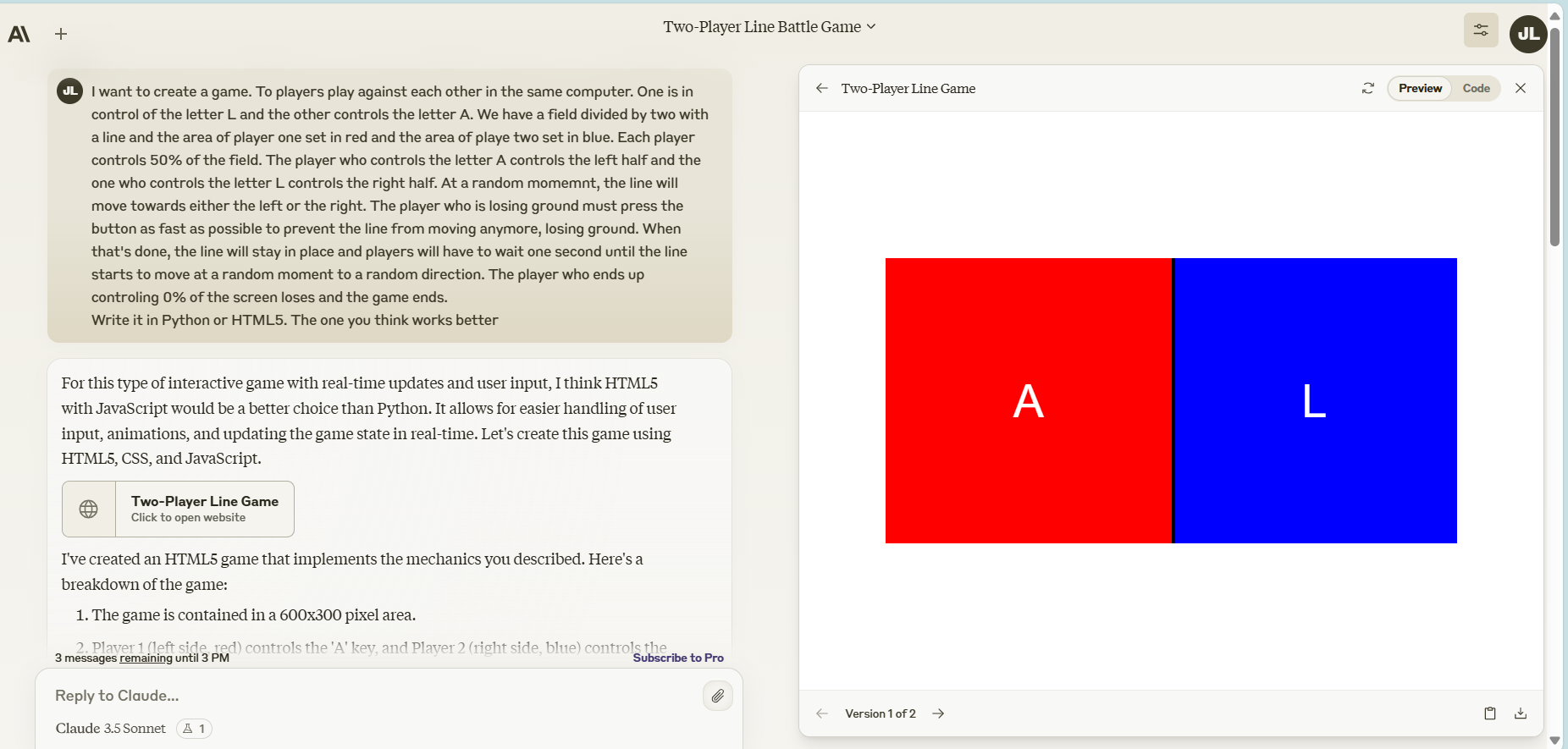
我们通过要求两个模型创建一个游戏来测试Claude的编码能力。然而,与其要求复制已知游戏不同,这些游戏可能是它们的训练数据集的一部分,我们想出了一个测量两名玩家反应时间的游戏的想法。
提示:
我想创建一个游戏。
两名玩家在同一台计算机上对战。一个玩家控制字母L,另一个控制字母A。
我们有一个被一条线分成两半的领域。每个玩家控制领域的50%。控制A的玩家控制左半部分,控制L的玩家控制右半部分。
在随机时刻,线会向左或向右移动。
失去地盘的玩家必须尽快按下按钮,防止线继续移动。
完成后,线将停留在原地,玩家必须等待直到线在随机时刻向随机位置移动。
最终控制0%屏幕的玩家输掉游戏。
用Python或HTML5编写。你认为哪个更好用
Claude 3.5 Sonnet表现出色。它不仅按要求交付了游戏,还主动加入了一个基本但功能齐全的图形界面,带有视觉提示,使游戏更容易理解。
Claude迅速完成了这个任务,展示了在不到10秒内展示了增强的编码能力。
ChatGPT也成功创建了游戏,符合给定的规格。然而,生成任务的时间较长(将近45秒),并且没有包括额外的功能,如文本提示,以使游戏更容易理解。
此外,游戏的节奏要慢得多,这违背了反应游戏的初衷,而且“游戏结束”弹窗没有显示谁赢了。
获胜者:Claude 3.5 Sonnet获胜。它能够快速生成更全面和功能丰富的代码,包括像图形界面这样的额外功能,展示了卓越的编码能力。
此外,其“Artifacts”功能非常方便,可以在聊天机器人的界面中测试代码,而无需将代码复制粘贴到外部工具中——这是ChatGPT的工作方式。
我们要求两个模型根据一个特定的想法创作一个虚构故事。我们想测试模型的创造力,他们的故事是否丰富引人入胜,以及他们对于创意作家来说整体表现如何。
提示:
写一个关于Jose Lanz的短篇故事,他是来自2150年的时间旅行者,前往1000年。确保你的叙述充满生动的描述性语言,无论你选择什么,都要真实地描绘Jose的文化背景和外貌特征。
故事的核心应围绕着时间旅行悖论和试图解决或改变过去问题的徒劳,意图是改变当前时间线。强调未来存在的讽刺之处在于过去的存在就是现在的样子。尽管Jose有意影响1000年的事件,但他所采取的行动注定会发生,因为这些行动对2150年的存在是必要的。对这一悖论的认识是故事中的关键时刻。
Claude 3.5 Sonnet创作了一个自然流畅的叙述,具有引人入胜的结构。AI巧妙地融入了时间旅行悖论等复杂概念,创作了一个富有细微差别的故事,冒险创造。
在它的版本中,主人公试图阻止一个数学概念的发展,这个概念导致了他那个时代的灾难性后果。在与研究人员社会融合并似乎阻止了这个概念的发展后,他返回发现自己实际上是他所创造的时间悖论的关键部分,甚至在古代文献中找到了对自己的引用。

ChatGPT生成了一个符合要求的故事,但走了更为可预测的道路。虽然能干,但其叙述缺乏Claude故事所展现的深度和创意风采。
GPT-4o创作了一个直截了当的故事,主人公试图通过与过去的萨满分享先进的教义来防止能源危机。然而,当他返回到自己的时间线时,他发现历史重演,一切都没有改变。

获胜者:Claude在创意写作方面获胜。它产生更具想象力、细腻和结构良好的叙述能力使其脱颖而出,使其成为需要创造力的任务的优越选择。
例如,很容易想象融入一个社会可能会影响一群研究人员并阻止他们发现某事。相比之下,与萨满分享先进知识来防止能源危机则不太合理。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKx资讯仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。
比特币Rollup Citrea在测试网上部署了基于BitVM的桥接器“Clementine”。
利用比特币的安全性进行无信任资产转移

TrustToken、TrueCoin与SEC就稳定币投资的欺诈指控达成和解
industry-frontier